This allows us to store complicated “shapes” in very little storage space, because we can look up these numerical stand-ins in a table- just like the Chinese Telegraph codes.
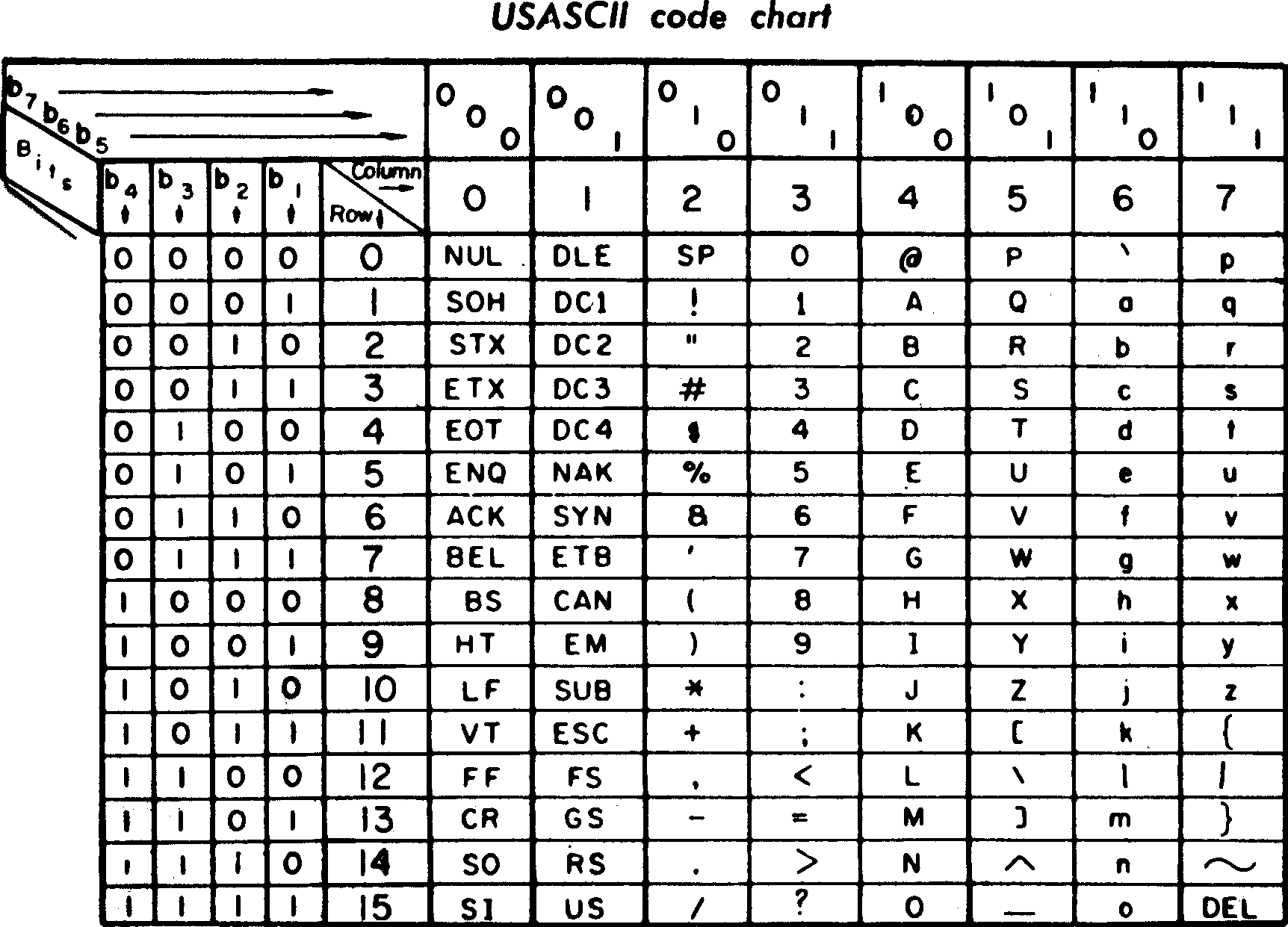
US-ASCII Code Chart, February 1972, General Electric Data communication Product Dept., Waynesboro, Virginia. Image from the Wikimedia Commons.
ASCII was adopted by all U.S. computer manufacturers except for IBM, which, unwilling to give up the decades of dominance afforded by Baudot code developed a different proprietary 8 bit character code (2^8 = 256 code points) called EBCDIC [pronounced eb-see-dick], which stands for "Extended Binary Coded Decimal Interchange Code." It was particularly incomprehensible, the butt of many jokes, and generally not adopted.
U.S. computer companies were by this point selling in international markers, and ASCII became an “international standard”. Of course, this meant adapting ASCII to individual countries. The International Organization for Standardization in Geneva recommended using ASCII code as-is, but with 10 code points to be left open for “national variants”.
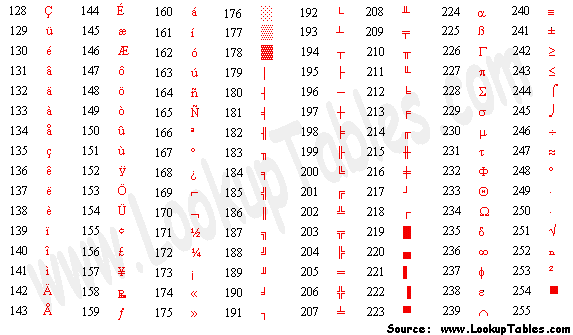
Of course, so many languages do not inherently use Latin characters, and even those that do may have more than 10 “national variants” to fit into a table. These countries often had their own or heavily adapted standards. These were often specific to the individual language, but generally computer makers defined unique country “code pages” that used the undefined space from 128-255 in the extended ASCII table, mapping it to various characters they needed.
Extended ASCII Table. Image from Lookuptables.com.
Despite the obvious flaws with this system (more on that later), ASCII was by far the dominant text scheme on the early internet.
No conversation around ASCII would be complete without discussing ASCII art, which was a culturally seminal part of the early internet. ASCII art is made of those 128 (96) printable characters, and was used on forums, in BBSes, on USEnet, as email sign-offs, and as graphics in early (and some contemporary!) games. ASCII art partly rose because early printers often lacked graphics ability and so characters could be used instead to represent images- a language borrowed from typewriter art. It also served as a visual representation when images were too big to transmit over low bandwidths.
Despite this prevalence of ASCII in the 1970s-1990s, 128 characters plus an additional undefined 128 obviously aren’t enough for the entire world: code pages (lookup tables that definied what number mapped to what letter) varied by country. This works fine in theory, and certainly was a functional stopgap for the internal usage of say, an American computer by an Iranian company.
However, when computers with different code pages exchange data it truly all goes to hell. For instance, if you send an email from a Greek Cyrillic code-page computer to a Russian code-page computer, the piece of text that arrived would be incomprehensible. This is because the character that is mapped to, say, 166 would be totally different on each computer. Although cross-language data transmission like this was always a problem, it truly entered center stage with the proliferation of the World Wide Web.
There were some attempts to figure this out automatically in early browsers. These were schemas that would attempt to detect the language of a website by counting characters, and finding the most common codepoints to match with a language (in English, it’d be the letters E and T). However, this was incredibly unreliable, and did little to fix the scramble of text.
This problem is essentially why ASCII (and ISO and ANSI, highly related text schemas) are practically defunct. UTF-8 is the standard text encoding format of the web since the early 2000s, which will be looked at in the next chaper: Unicode, plaintext, and emoji.
 US-ASCII Code Chart, February 1972, General Electric Data communication Product Dept., Waynesboro, Virginia. Image from the Wikimedia Commons.ASCII was adopted by all U.S. computer manufacturers except for IBM, which, unwilling to give up the decades of dominance afforded by Baudot code developed a different proprietary 8 bit character code (2^8 = 256 code points) called EBCDIC [pronounced eb-see-dick], which stands for "Extended Binary Coded Decimal Interchange Code." It was particularly incomprehensible, the butt of many jokes, and generally not adopted. U.S. computer companies were by this point selling in international markers, and ASCII became an “international standard”. Of course, this meant adapting ASCII to individual countries. The International Organization for Standardization in Geneva recommended using ASCII code as-is, but with 10 code points to be left open for “national variants”. Of course, so many languages do not inherently use Latin characters, and even those that do may have more than 10 “national variants” to fit into a table. These countries often had their own or heavily adapted standards. These were often specific to the individual language, but generally computer makers defined unique country “code pages” that used the undefined space from 128-255 in the extended ASCII table, mapping it to various characters they needed.Extended ASCII Table. Image from Lookuptables.com.Despite the obvious flaws with this system (more on that later), ASCII was by far the dominant text scheme on the early internet. No conversation around ASCII would be complete without discussing ASCII art, which was a culturally seminal part of the early internet. ASCII art is made of those 128 (96) printable characters, and was used on forums, in BBSes, on USEnet, as email sign-offs, and as graphics in early (and some contemporary!) games. ASCII art partly rose because early printers often lacked graphics ability and so characters could be used instead to represent images- a language borrowed from typewriter art. It also served as a visual representation when images were too big to transmit over low bandwidths.(From http://www.ascii-art.de/ascii/ab/armadillo.txt)Despite this prevalence of ASCII in the 1970s-1990s, 128 characters plus an additional undefined 128 obviously aren’t enough for the entire world: code pages (lookup tables that definied what number mapped to what letter) varied by country. This works fine in theory, and certainly was a functional stopgap for the internal usage of say, an American computer by an Iranian company. However, when computers with different code pages exchange data it truly all goes to hell. For instance, if you send an email from a Greek Cyrillic code-page computer to a Russian code-page computer, the piece of text that arrived would be incomprehensible. This is because the character that is mapped to, say, 166 would be totally different on each computer. Although cross-language data transmission like this was always a problem, it truly entered center stage with the proliferation of the World Wide Web. There were some attempts to figure this out automatically in early browsers. These were schemas that would attempt to detect the language of a website by counting characters, and finding the most common codepoints to match with a language (in English, it’d be the letters E and T). However, this was incredibly unreliable, and did little to fix the scramble of text. This problem is essentially why ASCII (and ISO and ANSI, highly related text schemas) are practically defunct. UTF-8 is the standard text encoding format of the web since the early 2000s, which will be looked at in the next chaper: Unicode, plaintext, and emoji.
US-ASCII Code Chart, February 1972, General Electric Data communication Product Dept., Waynesboro, Virginia. Image from the Wikimedia Commons.ASCII was adopted by all U.S. computer manufacturers except for IBM, which, unwilling to give up the decades of dominance afforded by Baudot code developed a different proprietary 8 bit character code (2^8 = 256 code points) called EBCDIC [pronounced eb-see-dick], which stands for "Extended Binary Coded Decimal Interchange Code." It was particularly incomprehensible, the butt of many jokes, and generally not adopted. U.S. computer companies were by this point selling in international markers, and ASCII became an “international standard”. Of course, this meant adapting ASCII to individual countries. The International Organization for Standardization in Geneva recommended using ASCII code as-is, but with 10 code points to be left open for “national variants”. Of course, so many languages do not inherently use Latin characters, and even those that do may have more than 10 “national variants” to fit into a table. These countries often had their own or heavily adapted standards. These were often specific to the individual language, but generally computer makers defined unique country “code pages” that used the undefined space from 128-255 in the extended ASCII table, mapping it to various characters they needed.Extended ASCII Table. Image from Lookuptables.com.Despite the obvious flaws with this system (more on that later), ASCII was by far the dominant text scheme on the early internet. No conversation around ASCII would be complete without discussing ASCII art, which was a culturally seminal part of the early internet. ASCII art is made of those 128 (96) printable characters, and was used on forums, in BBSes, on USEnet, as email sign-offs, and as graphics in early (and some contemporary!) games. ASCII art partly rose because early printers often lacked graphics ability and so characters could be used instead to represent images- a language borrowed from typewriter art. It also served as a visual representation when images were too big to transmit over low bandwidths.(From http://www.ascii-art.de/ascii/ab/armadillo.txt)Despite this prevalence of ASCII in the 1970s-1990s, 128 characters plus an additional undefined 128 obviously aren’t enough for the entire world: code pages (lookup tables that definied what number mapped to what letter) varied by country. This works fine in theory, and certainly was a functional stopgap for the internal usage of say, an American computer by an Iranian company. However, when computers with different code pages exchange data it truly all goes to hell. For instance, if you send an email from a Greek Cyrillic code-page computer to a Russian code-page computer, the piece of text that arrived would be incomprehensible. This is because the character that is mapped to, say, 166 would be totally different on each computer. Although cross-language data transmission like this was always a problem, it truly entered center stage with the proliferation of the World Wide Web. There were some attempts to figure this out automatically in early browsers. These were schemas that would attempt to detect the language of a website by counting characters, and finding the most common codepoints to match with a language (in English, it’d be the letters E and T). However, this was incredibly unreliable, and did little to fix the scramble of text. This problem is essentially why ASCII (and ISO and ANSI, highly related text schemas) are practically defunct. UTF-8 is the standard text encoding format of the web since the early 2000s, which will be looked at in the next chaper: Unicode, plaintext, and emoji.