In short, all this history means that at the very root of the modern internet, there exists a character format invented in the 1870’s, computerized as ASCII in the 1960’s, modernized for the web with Unicode the 1990’s, and broadly adopted through UTF-8’s majority use in 2007.
(This person is just as enthusiastic about text encoding as I am, and is the clearest explanation of UTF-8 I’ve ever seen- give it a watch, even if you skip the rest of the videos in this text.)
* * * What is UTF?
UTF(-8, -16, -32, etc) describes a character encoding. It is basically a big lookup table.
Although I won't be getting into technical details in depth, I wanted to mention that there are several different UTF encoding schemes. UTF-8 is the standard, as it is backwards compatible with ASCII. A UTF-8 file that only contains ASCII characters is identical to an ASCII file. Roughly 95%~ of the internet is in UTF-8.
UTF-16 and -32 are incompatible with ASCII. They contain many zero-bytes, and need an Unicode-aware program to display correctly. They also do not allow ‘null-terminated string handling’. However, they are faster than UTF-8, and are used internally by many systems (like Windows, Javascript, and Java). There is also a big Chinese government standard called GB 18030 which is a Unicode Transformation format.
Additional fiddly details about these differences can be found at Unicode and You, if desired.
* * * What is Unicode?
Unicode describes the standard for the consistent encoding and handling of text. Unicode 12.1, which came out in May, has 137,994 characters in 150 different scripts, as well as symbol sets (like wingdings and box drawing), and, of course, Emoji.
The Unicode Standard is a set of code charts, data files, and rules for all the weird specifics of rendering the world’s scripts on a computer.
The Unicode Consortium is a nonprofit in Mountain View, California, that makes these rules. It is an open-membership organization and individual dues are between $35 and $75 a year. However, full corporate membership is $21,000 a year, and includes the right to vote on both technical committees and the board. Because of this, these are the (current in 2020 members):
Full Members (Voting):
Institutional Members (Voting):
Supporting Members (Voting):
Associate Members:
These are the companies, governments, and nonprofits that make major decisions about how we all read on computers. The Unicode Consortium’s mission is “Everyone in the world should be able to use their own language on phones and computers.” This language is, on a whole, generous and hopeful, but it is perhaps worth taking this with a grain of salt - more on this later.
* * * Unicode planes
There are 17 possible ‘planes’ in Unicode, numbered from 0-16. The 17 planes can accommodate 1,114,112 code points in total. Of these, 2,048 are surrogates (used to make the pairs in UTF-16), 66 are non-characters, and 137,468 are reserved for private use, leaving 974,530 for public assignment.
So far, only 6 of those 17 planes have any codepoints allocated for characters. Each plane has 65,536 possible codepoints total.
The “Basic Multilingual plane” in Unicode is the first (0) plane. It has 65,472 allocated code points, and 55,445 assigned characters (‘assigned characters’ ignores non characters and surrogate control points).
The bulk of the characters in the Basic Multilingual plane are Chinese, Japanese, and Korean (CJK). However, it includes a pretty dramatic range of scripts and symbols! Most of the world’s writing is in Plane 0.
Plane 1, the Supplementary Multilingual Plane, contains historic (dead language) scripts like Cuneiform, some modern and new scripts like Osage, as well as musical notation, emoji, and game symbols. It has 23,568 code points and 21,353 assigned characters.
Plane 2, the Supplementary Ideographic Plane, is all CJK characters.
Possibly the biggest thing that Unicode is doing is following this idea of Han unification. Han unification is an effort by Unicode to map multiple character sets of the so-called CJK languages into a single set of unified characters. Han characters are a common feature of written Chinese (hanzi), Japanese (kanji), and Korean (hanja), although they generally have regional variants.
Unicode has attempted to unify all of the variants by unifying these different character glyphs as “graphemes”. This inherently comes with a culling of historical and regional variants - a process that has caused significant controversy. (An alternate, generally non-adopted encoding, TRON proposes a 150 million code point space without unification.)
The rest of the planes are mostly private or empty.
* * * Unicode blocks
“Blocks” in Unicode are various sizes and basically just describe what’s inside them.
Here are some neat ones:
Runic! Alchemical Symbols!
One of the things that the Unicode Consortium does is digitize scripts from indigenous communities, like the Unified Canadian Aboriginal Syllabics block.
Also, blocks like Arabic are interesting to use on a western computer because the text reads right-to-left. Or Mongolian, which reads top-down.
There are lots and lots of cute characters in Unicode. See- Arrows, Miscellaneous Technical, Box Drawing, Block Elements, Geometric Shapes, Dingbats, Miscellaneous Symbols, Supplemental Arrows-A, Miscellaneous Symbols and Arrows, Ornamental Dingbats.
There is a block of Braille Patterns, a likely-influence for Morse code which has turned, very slowly, into the very basis of their own representation.
Medefaidrin, a constructed Christian sacred language from Ibibio congregation in Nigeria in the 1930s.
Cuneiform - which is wild to see on a screen because it was made expressly to be written in clay with a stylus. (Cuneiform Numbers and Punctuation, Early Dynastic Cuneiform)
Glagolitic, which was invented by Saint Cyril in the 800s to translate scripture into Slavonic.
Mahjong Tiles, Domino Tiles, Playing Cards, Chess Symbols.
I truly love just moving around these blocks of characters, they give you a sense of the density and richness of text and script and writing and thought in our world.
* * * Combining characters
Combining characters are characters that are meant to modify other characters by stacking on top. They go after a character. Most come from the International Phonetic Alphabet. This is the basis of the meme format "Zalgo Text".
Combining characters can behave erratically when combined in ways that are unexpected. There are many generators that will transform your text into ~Zalgo~.
Try making a post on a social media site with them - if those services haven’t prepped for this circumstance, you can escape the confines of the box that your text is supposed to live in, sometimes quite dramatically.
Here are some Unicode blocks that contain combining characters: Combining Diacritical Marks, Combining Diacritical Marks Extended, Combining Diacritical Marks Supplement, Combining Diacritical Marks for Symbols, and Combining Half Marks.
* * * Emoji 😬
Emoji are probably the reason the Unicode Consortium has been in such a public light in the last decade.
Emoji, (sometimes called emoticons) were only added to Unicode in 2010. They were added in response to Japanese mobile carriers implementing a symbol set into currently unused blocks, and a need to standardize that choice.
Before this standardization, Japanese mobile carriers had used empty codepoints to assign little icons in their phone operating systems. However, much like the scrambled ASCII text we talked about earlier, these were not standardized from carrier to carrier, and these texts would arrive deeply scrambled - a phenomenon that earned the name Mojibake.
The Unicode Consortium originally only implemented 716 Emoji in Unicode 6.0, and almost all of them were about emotions, or very directly relevant to life in Japan (which is why will still have so many about specific train and tram types). Since then, additions have been very publicly anticipated.
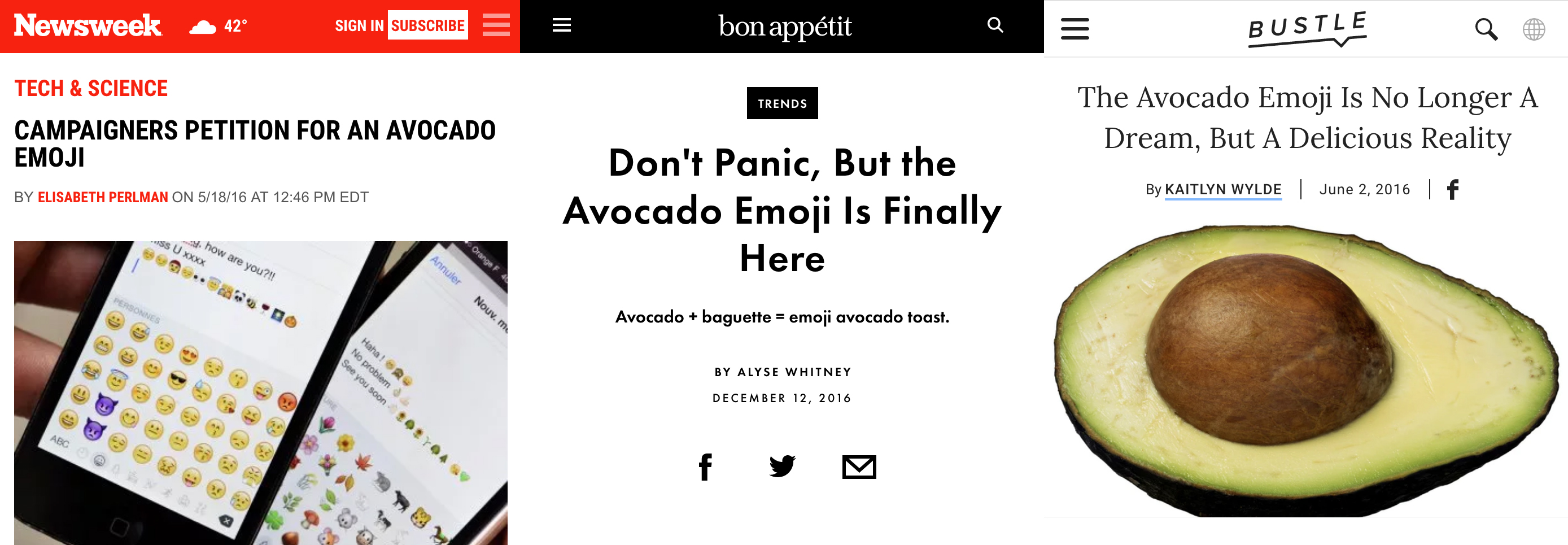
Three avocado-centric headlines, from Newsweek, Bon Appétit, and Bustle.
For an organization that encodes hundreds of scripts from all over the world, the Unicode Consortium was not expecting Emoji to take on the life that they did. I was a student member at the time, and there was a fair amount of consternation from the Consortium about the role of Emoji. Some felt that their mission as an organization was to representing the world’s languages in digital space, but- all of a sudden- they were instead radically shifting contemporary written culture.
Emoji also meant an influx of new members, who were on a whole younger and more design-oriented, or directly tied into social media companies as opposed to working in operating system or computer hardware design.
One of the most important conversations in Emoji space since then has been about representation. The avocado emoji in some ways is a part of this conversation- despite the avocado becoming a bit of a meme about millennial and toast, it is also a fundamental food for many many people in the world. Despite the meme-ability of “finally, an avocado!” it is truly worth asking what it meant to have mochi, but not avocado in a communication format for so long.
In 2015, implementing representative skin tones for people Emoji came to the forefront of these conversations. These debates were heated, with wide variation in proposals. Mark Davis from Google and Peter Edberg from Apple ended up winning this argument, with the 5 skin-tone range modifiers you’ve probably all seen, the EMOJI MODIFIER FITZPATRICK TYPE-1-2, -3, -4, -5, and -6 (U+1F3FB–U+1F3FF): 🏻 🏼 🏽 🏾 🏿, and a default of yellow.
One of the aspects of Emoji that you may have noticed is the cross-platform confusion that comes from different designers and systems. “Pile of poo” might look pretty different from one platform to another. This was also true of people and emoji, and it tied directly into conversations about representation. The “construction worker” emoji is a nice example: it was intended to be gender neutral, but most platforms implemented a masculine worker. Alternatively, the “dancer” emoji was eventually renamed to “woman dancing” because Apple implemented it as a salsa dancer in a red dress, a very flashy and gendered emoji that got a lot of use. 💃
The Unicode Consortium started to realize that if they didn’t include distinct modifiers and expectations around these code points that they might end up essentially unreadable from system to system, another type of Mojibake.
Here is a breakdown from Slate in 2016 of common misunderstood Emoji:
Watching this video it becomes clear that a lot of these designs are different now. The ways we use these symbols has changed entirely in only a few years! This is a concern for text and web archiving. Meaning changes for Emoji constantly, and their images are updated to boot- and a piece of text, saved simply as a series of numbers, will not save the version of the Emoji it was written with but will rather update to whatever is in that place in the table now.
Obviously, text and words also change meaning over time. But the quickness of change in this type of visual communication is notable.
There are now 2,823 Emoji: Here are some blocks that contain them: Emoticons!Transport and Map Symbols!Supplemental Symbols and Pictographs!Miscellaneous Symbols and Pictographs!* * * Plain text
Plain text is a basic but important idea to internalize when working with text data. Plain text, simply put, is data that is only characters of readable material.
In plain text, there is no formatting (bold, italics, font-size, color, etc), no structure (paragraphs, headers, etc), and no other objects that are encoded as binary (images, videos, etc).
Files that contain markup or HTML can be plain text, as long as that is in a directly human-readable form.
According to the Unicode Standard, plain text is:
* A pure sequence of character codes; plain Un-encoded text is therefore a sequence of Unicode character codes.
* The underlying content stream to which formatting can be applied.
* Public, standardized, and universally readable.
* Always interoperable between various programs, word editors, system architectures, etc. Almost all programming files are plain text.
You can turn rich text into plaintext by formatting it, or just by copy and pasting it into a place that doesn’t support rich text. If you turn “rich text” into plain text, you lose your styling. In most text editors, you can “make something plaintext”.
If you right-click on this page and hit "View Page Source", you can see the plaintext version of what you're looking at - the content stripped of invisible code and formatting.
* * * Fonts
Fonts are one of the final bits of the character encoding puzzle. Fonts map glyphs to code points. This is why you can “change the font” of a character, but the character remains “A”. Technically, you can map whatever to whatever if you make your own fonts, just like Wingdings, where ‘A’ is a peace symbol.
If your font doesn't have a glyph for a particular character, some browsers or software applications will look for the missing glyphs in other fonts on your system. Otherwise you will typically see a box (□ or ▯), a question mark in a diamond (�), a Geta mark (〓) or, sometimes, some other character instead.
(This is a bit of an underselling of how complex fonts can be, which are a practice all in and of themselves.)
There is one font that tries to have all of Unicode available in it, the open-source GNU Unifont.
Complete character table of the GNU Unifont version 10.0.7 (BMP & Non-BMP) – 256 glyphs per row.
* * * Filetypes
Filetypes are, ultimately, an illusion (more on this in the next chapter), but they do tell your computer how to deal with the content within. A .doc document will open in Microsoft Word, while an .html document will open in the browser. Each of these applications has particular tools to deal with the content of these files.
Here is a short list of some common filetypes that deal with text:
.txt - plaintext, can be used by most applications
.rtf - “rich text format”, a styled .txt
.doc or .docx - made by microsoft word, some other things can import it
.pages - made by apple pages. limited interoperability- better to export as a .docx.
.csv - “comma separated values”, content separated via comma, often visualized as a table
.pdf - an adobe file type “Portable Document Format” that can include text, fonts, images, buttons, all sorts of stuff.
.html (or .htm) - a plaintext file parsed in a certain way by the browser
.js - a plaintext file containing javascript code
.css - a plaintext file containing “CSS”, cascading style sheets
Most programming languages also save their code files as plaintext (.py, python, .rb, ruby, etc.)
However, technically you can open whatever you want as a .txt file. You might get garbled nonsense, but it’s still all text in there eventually, even music and 3d models and videogames.
This is because of what text “is” on a computer. More on this in Chapter V - A letter is an idea: exercises and experiments.
Institutional Members (Voting):
Supporting Members (Voting):
Associate Members:
These are the companies, governments, and nonprofits that make major decisions about how we all read on computers. The Unicode Consortium’s mission is “Everyone in the world should be able to use their own language on phones and computers.” This language is, on a whole, generous and hopeful, but it is perhaps worth taking this with a grain of salt - more on this later. * * * Unicode planes There are 17 possible ‘planes’ in Unicode, numbered from 0-16. The 17 planes can accommodate 1,114,112 code points in total. Of these, 2,048 are surrogates (used to make the pairs in UTF-16), 66 are non-characters, and 137,468 are reserved for private use, leaving 974,530 for public assignment. So far, only 6 of those 17 planes have any codepoints allocated for characters. Each plane has 65,536 possible codepoints total. The “Basic Multilingual plane” in Unicode is the first (0) plane. It has 65,472 allocated code points, and 55,445 assigned characters (‘assigned characters’ ignores non characters and surrogate control points). The bulk of the characters in the Basic Multilingual plane are Chinese, Japanese, and Korean (CJK). However, it includes a pretty dramatic range of scripts and symbols! Most of the world’s writing is in Plane 0. Plane 1, the Supplementary Multilingual Plane, contains historic (dead language) scripts like Cuneiform, some modern and new scripts like Osage, as well as musical notation, emoji, and game symbols. It has 23,568 code points and 21,353 assigned characters. Plane 2, the Supplementary Ideographic Plane, is all CJK characters. Possibly the biggest thing that Unicode is doing is following this idea of Han unification. Han unification is an effort by Unicode to map multiple character sets of the so-called CJK languages into a single set of unified characters. Han characters are a common feature of written Chinese (hanzi), Japanese (kanji), and Korean (hanja), although they generally have regional variants. Unicode has attempted to unify all of the variants by unifying these different character glyphs as “graphemes”. This inherently comes with a culling of historical and regional variants - a process that has caused significant controversy. (An alternate, generally non-adopted encoding, TRON proposes a 150 million code point space without unification.) The rest of the planes are mostly private or empty. * * * Unicode blocks “Blocks” in Unicode are various sizes and basically just describe what’s inside them. Here are some neat ones: Runic! Alchemical Symbols! One of the things that the Unicode Consortium does is digitize scripts from indigenous communities, like the Unified Canadian Aboriginal Syllabics block. Also, blocks like Arabic are interesting to use on a western computer because the text reads right-to-left. Or Mongolian, which reads top-down. There are lots and lots of cute characters in Unicode. See- Arrows, Miscellaneous Technical, Box Drawing, Block Elements, Geometric Shapes, Dingbats, Miscellaneous Symbols, Supplemental Arrows-A, Miscellaneous Symbols and Arrows, Ornamental Dingbats. There is a block of Braille Patterns, a likely-influence for Morse code which has turned, very slowly, into the very basis of their own representation. Medefaidrin, a constructed Christian sacred language from Ibibio congregation in Nigeria in the 1930s. Cuneiform - which is wild to see on a screen because it was made expressly to be written in clay with a stylus. (Cuneiform Numbers and Punctuation, Early Dynastic Cuneiform) Glagolitic, which was invented by Saint Cyril in the 800s to translate scripture into Slavonic. Mahjong Tiles, Domino Tiles, Playing Cards, Chess Symbols. I truly love just moving around these blocks of characters, they give you a sense of the density and richness of text and script and writing and thought in our world. * * * Combining characters Combining characters are characters that are meant to modify other characters by stacking on top. They go after a character. Most come from the International Phonetic Alphabet. This is the basis of the meme format "Zalgo Text".
 Three avocado-centric headlines, from Newsweek, Bon Appétit, and Bustle.For an organization that encodes hundreds of scripts from all over the world, the Unicode Consortium was not expecting Emoji to take on the life that they did. I was a student member at the time, and there was a fair amount of consternation from the Consortium about the role of Emoji. Some felt that their mission as an organization was to representing the world’s languages in digital space, but- all of a sudden- they were instead radically shifting contemporary written culture. Emoji also meant an influx of new members, who were on a whole younger and more design-oriented, or directly tied into social media companies as opposed to working in operating system or computer hardware design. One of the most important conversations in Emoji space since then has been about representation. The avocado emoji in some ways is a part of this conversation- despite the avocado becoming a bit of a meme about millennial and toast, it is also a fundamental food for many many people in the world. Despite the meme-ability of “finally, an avocado!” it is truly worth asking what it meant to have mochi, but not avocado in a communication format for so long.
Three avocado-centric headlines, from Newsweek, Bon Appétit, and Bustle.For an organization that encodes hundreds of scripts from all over the world, the Unicode Consortium was not expecting Emoji to take on the life that they did. I was a student member at the time, and there was a fair amount of consternation from the Consortium about the role of Emoji. Some felt that their mission as an organization was to representing the world’s languages in digital space, but- all of a sudden- they were instead radically shifting contemporary written culture. Emoji also meant an influx of new members, who were on a whole younger and more design-oriented, or directly tied into social media companies as opposed to working in operating system or computer hardware design. One of the most important conversations in Emoji space since then has been about representation. The avocado emoji in some ways is a part of this conversation- despite the avocado becoming a bit of a meme about millennial and toast, it is also a fundamental food for many many people in the world. Despite the meme-ability of “finally, an avocado!” it is truly worth asking what it meant to have mochi, but not avocado in a communication format for so long. From Inclusive Illustration Research: How Emojis Handle Skin Tones, by Jason Li.In 2015, implementing representative skin tones for people Emoji came to the forefront of these conversations. These debates were heated, with wide variation in proposals. Mark Davis from Google and Peter Edberg from Apple ended up winning this argument, with the 5 skin-tone range modifiers you’ve probably all seen, the EMOJI MODIFIER FITZPATRICK TYPE-1-2, -3, -4, -5, and -6 (U+1F3FB–U+1F3FF): 🏻 🏼 🏽 🏾 🏿, and a default of yellow. One of the aspects of Emoji that you may have noticed is the cross-platform confusion that comes from different designers and systems. “Pile of poo” might look pretty different from one platform to another. This was also true of people and emoji, and it tied directly into conversations about representation. The “construction worker” emoji is a nice example: it was intended to be gender neutral, but most platforms implemented a masculine worker. Alternatively, the “dancer” emoji was eventually renamed to “woman dancing” because Apple implemented it as a salsa dancer in a red dress, a very flashy and gendered emoji that got a lot of use. 💃 The Unicode Consortium started to realize that if they didn’t include distinct modifiers and expectations around these code points that they might end up essentially unreadable from system to system, another type of Mojibake. Here is a breakdown from Slate in 2016 of common misunderstood Emoji: Watching this video it becomes clear that a lot of these designs are different now. The ways we use these symbols has changed entirely in only a few years! This is a concern for text and web archiving. Meaning changes for Emoji constantly, and their images are updated to boot- and a piece of text, saved simply as a series of numbers, will not save the version of the Emoji it was written with but will rather update to whatever is in that place in the table now. Obviously, text and words also change meaning over time. But the quickness of change in this type of visual communication is notable. There are now 2,823 Emoji: Here are some blocks that contain them: Emoticons! Transport and Map Symbols! Supplemental Symbols and Pictographs! Miscellaneous Symbols and Pictographs! * * * Plain text Plain text is a basic but important idea to internalize when working with text data. Plain text, simply put, is data that is only characters of readable material. In plain text, there is no formatting (bold, italics, font-size, color, etc), no structure (paragraphs, headers, etc), and no other objects that are encoded as binary (images, videos, etc). Files that contain markup or HTML can be plain text, as long as that is in a directly human-readable form. According to the Unicode Standard, plain text is: * A pure sequence of character codes; plain Un-encoded text is therefore a sequence of Unicode character codes. * The underlying content stream to which formatting can be applied. * Public, standardized, and universally readable. * Always interoperable between various programs, word editors, system architectures, etc. Almost all programming files are plain text. You can turn rich text into plaintext by formatting it, or just by copy and pasting it into a place that doesn’t support rich text. If you turn “rich text” into plain text, you lose your styling. In most text editors, you can “make something plaintext”. If you right-click on this page and hit "View Page Source", you can see the plaintext version of what you're looking at - the content stripped of invisible code and formatting. * * * Fonts Fonts are one of the final bits of the character encoding puzzle. Fonts map glyphs to code points. This is why you can “change the font” of a character, but the character remains “A”. Technically, you can map whatever to whatever if you make your own fonts, just like Wingdings, where ‘A’ is a peace symbol. If your font doesn't have a glyph for a particular character, some browsers or software applications will look for the missing glyphs in other fonts on your system. Otherwise you will typically see a box (□ or ▯), a question mark in a diamond (�), a Geta mark (〓) or, sometimes, some other character instead. (This is a bit of an underselling of how complex fonts can be, which are a practice all in and of themselves.) There is one font that tries to have all of Unicode available in it, the open-source GNU Unifont.
From Inclusive Illustration Research: How Emojis Handle Skin Tones, by Jason Li.In 2015, implementing representative skin tones for people Emoji came to the forefront of these conversations. These debates were heated, with wide variation in proposals. Mark Davis from Google and Peter Edberg from Apple ended up winning this argument, with the 5 skin-tone range modifiers you’ve probably all seen, the EMOJI MODIFIER FITZPATRICK TYPE-1-2, -3, -4, -5, and -6 (U+1F3FB–U+1F3FF): 🏻 🏼 🏽 🏾 🏿, and a default of yellow. One of the aspects of Emoji that you may have noticed is the cross-platform confusion that comes from different designers and systems. “Pile of poo” might look pretty different from one platform to another. This was also true of people and emoji, and it tied directly into conversations about representation. The “construction worker” emoji is a nice example: it was intended to be gender neutral, but most platforms implemented a masculine worker. Alternatively, the “dancer” emoji was eventually renamed to “woman dancing” because Apple implemented it as a salsa dancer in a red dress, a very flashy and gendered emoji that got a lot of use. 💃 The Unicode Consortium started to realize that if they didn’t include distinct modifiers and expectations around these code points that they might end up essentially unreadable from system to system, another type of Mojibake. Here is a breakdown from Slate in 2016 of common misunderstood Emoji: Watching this video it becomes clear that a lot of these designs are different now. The ways we use these symbols has changed entirely in only a few years! This is a concern for text and web archiving. Meaning changes for Emoji constantly, and their images are updated to boot- and a piece of text, saved simply as a series of numbers, will not save the version of the Emoji it was written with but will rather update to whatever is in that place in the table now. Obviously, text and words also change meaning over time. But the quickness of change in this type of visual communication is notable. There are now 2,823 Emoji: Here are some blocks that contain them: Emoticons! Transport and Map Symbols! Supplemental Symbols and Pictographs! Miscellaneous Symbols and Pictographs! * * * Plain text Plain text is a basic but important idea to internalize when working with text data. Plain text, simply put, is data that is only characters of readable material. In plain text, there is no formatting (bold, italics, font-size, color, etc), no structure (paragraphs, headers, etc), and no other objects that are encoded as binary (images, videos, etc). Files that contain markup or HTML can be plain text, as long as that is in a directly human-readable form. According to the Unicode Standard, plain text is: * A pure sequence of character codes; plain Un-encoded text is therefore a sequence of Unicode character codes. * The underlying content stream to which formatting can be applied. * Public, standardized, and universally readable. * Always interoperable between various programs, word editors, system architectures, etc. Almost all programming files are plain text. You can turn rich text into plaintext by formatting it, or just by copy and pasting it into a place that doesn’t support rich text. If you turn “rich text” into plain text, you lose your styling. In most text editors, you can “make something plaintext”. If you right-click on this page and hit "View Page Source", you can see the plaintext version of what you're looking at - the content stripped of invisible code and formatting. * * * Fonts Fonts are one of the final bits of the character encoding puzzle. Fonts map glyphs to code points. This is why you can “change the font” of a character, but the character remains “A”. Technically, you can map whatever to whatever if you make your own fonts, just like Wingdings, where ‘A’ is a peace symbol. If your font doesn't have a glyph for a particular character, some browsers or software applications will look for the missing glyphs in other fonts on your system. Otherwise you will typically see a box (□ or ▯), a question mark in a diamond (�), a Geta mark (〓) or, sometimes, some other character instead. (This is a bit of an underselling of how complex fonts can be, which are a practice all in and of themselves.) There is one font that tries to have all of Unicode available in it, the open-source GNU Unifont. Complete character table of the GNU Unifont version 10.0.7 (BMP & Non-BMP) – 256 glyphs per row.* * * Filetypes Filetypes are, ultimately, an illusion (more on this in the next chapter), but they do tell your computer how to deal with the content within. A .doc document will open in Microsoft Word, while an .html document will open in the browser. Each of these applications has particular tools to deal with the content of these files. Here is a short list of some common filetypes that deal with text: .txt - plaintext, can be used by most applications .rtf - “rich text format”, a styled .txt .doc or .docx - made by microsoft word, some other things can import it .pages - made by apple pages. limited interoperability- better to export as a .docx. .csv - “comma separated values”, content separated via comma, often visualized as a table .pdf - an adobe file type “Portable Document Format” that can include text, fonts, images, buttons, all sorts of stuff. .html (or .htm) - a plaintext file parsed in a certain way by the browser .js - a plaintext file containing javascript code .css - a plaintext file containing “CSS”, cascading style sheets Most programming languages also save their code files as plaintext (.py, python, .rb, ruby, etc.) However, technically you can open whatever you want as a .txt file. You might get garbled nonsense, but it’s still all text in there eventually, even music and 3d models and videogames. This is because of what text “is” on a computer. More on this in Chapter V - A letter is an idea: exercises and experiments.
Complete character table of the GNU Unifont version 10.0.7 (BMP & Non-BMP) – 256 glyphs per row.* * * Filetypes Filetypes are, ultimately, an illusion (more on this in the next chapter), but they do tell your computer how to deal with the content within. A .doc document will open in Microsoft Word, while an .html document will open in the browser. Each of these applications has particular tools to deal with the content of these files. Here is a short list of some common filetypes that deal with text: .txt - plaintext, can be used by most applications .rtf - “rich text format”, a styled .txt .doc or .docx - made by microsoft word, some other things can import it .pages - made by apple pages. limited interoperability- better to export as a .docx. .csv - “comma separated values”, content separated via comma, often visualized as a table .pdf - an adobe file type “Portable Document Format” that can include text, fonts, images, buttons, all sorts of stuff. .html (or .htm) - a plaintext file parsed in a certain way by the browser .js - a plaintext file containing javascript code .css - a plaintext file containing “CSS”, cascading style sheets Most programming languages also save their code files as plaintext (.py, python, .rb, ruby, etc.) However, technically you can open whatever you want as a .txt file. You might get garbled nonsense, but it’s still all text in there eventually, even music and 3d models and videogames. This is because of what text “is” on a computer. More on this in Chapter V - A letter is an idea: exercises and experiments.{kind=link}