II - A long way to here
Text encoding on computers has deep roots.
Drum languages (especially in forested areas with low visibility, but lots of trees) have been used for long distance communication for ages- very effectively. Those who are fluent in a drum language can decode it just by listening. They often emulate the stresses and pauses of speech, but vary widely place-to-place. Drum languages were particularly prevalent in West Africa, in what is now Ghana and Nigeria.
Smoke signals have also been used to encode meaning (and sometimes, specific text) in many cultures throughout history, including in Ancient China, Ancient Greece, Australia, and in Indigenous North and South American communities. The Vatican still uses smoke signals when they select a new Pope.
Generally, smoke signals have a specific predetermined meaning according to their color/location/density/etc, but they have also been used with cyphers to encode characters to create written messages that are decrypted over time.
Optical communication in general has been used with ciphers and communication protocols, and systems of towers that employ long-distance vision as the primary connective force are prevalent throughout history.
The Greeks built Phryctoriae, which were usually built on mountaintops (much later called telegraph hills) about 20 miles apart. Torches were lit in combinations that correlated to specific characters (the Pyrseia), which was then repeated on the next tower, and the next tower, until it was decoded at the end of the line. (The Greeks also had a hydraulic semaphore system.) Mesoamerican pyramids, which were generally built within sightlines of one another, also likely made optical communication possible.
Although ciphers and codes continued to proliferate and change all through the 1000’s (see Bacon’s cipher, tap codes etc), very little infrastructural technology changed until the semaphore, which was developed in France in the late 1700s during the French Revolution.
The first well-known and widely adopted character code was probably Morse code, which was developed in the 1830s and 1840s by Samuel Morse (as well as Joseph Henry and Alfred Vail).

Samuel Morse, The Gallery of the Louvre 1831–33.
Morse was a painter. He developed Morse code on paper, but was fascinated with electromagnetism and worked with various physicists and engineers to produce a single-circuit electric telegraph- at the same time as one was produced for a rail company in Britain. The code also likely owes some roots to Braille, which was published only a few years earlier.
On May 24, 1844, Morse sent his collaborator Alfred Vail the historic first message via Morse in Telegraph. It read: “What hath God wrought!”


Maryland state historical marker commemorating the first telegraph message, located between US Highway 1 and railroad tracks in Beltsville, Maryland. Image from the Wikimedia Commons.
Although we think of Morse code as being used through machinery, you can also use it as manual code, generatable by hand on a telegraph key and decipherable by ear, or even tapped against a wall, or with a light or mirror.

Chart of the Morse code letters and numerals. Image from the Wikimedia Commons.
Just like the binary system used in modern computers, Morse is based on combinations of two possible values- a dot (or dit) and a dash (or dah). Unlike in modern computers, there are also pauses between these two values, also of two lengths, used to separate between letters.
A Dit takes - 1 unit of time
A Dah takes - - - 3 units of time
The pause between letters takes - - - 3 units of time
The pause between words takes - - - - - - - 7 units of time
Morse gave the most frequently used letters short and easy patterns, which reduced lengths of messages. For instance, ‘E’, the most common letter in English, is represented by a single dit, and ‘T’, the second most common, by a single dah. ‘Q’ is dah dah dit dah.
S.O.S., the internationally recognized distress signal, does not stand for any particular phrase - despite the proliferation of the phrase “Save Our Souls”. It was chosen instead because the letters are easy to remember and transmit - "S" is three dits, and "O" is three dahs.
(A sidenote - Morse did not do a study of texts to find the frequency of specific letters in English, but instead by going to printing presses and counting the individual pieces of type in each section. It worked well enough!)
Morse code originally only contained latin A-Z (with no distinction between upper and lower case), the Arabic numerals, and some punctuation. As you can imagine, this was limited and other versions of Morse quickly proliferated, sometimes responding to the needs of a local language to represent other characters.
A particularly interesting side-effect of Morse code was the existence of Hog-Morse (unrelated to Pig-Latin). Hog-Morse came from the new or inexperienced Morse operators to make errors when sending or receiving code. It is named after a simple example - "home" becoming "hog" because of a subtle error in timing on the last letter.
Morse code is very much tied to the telegraph, but it was not the only telegraph code to exist - far from it. In 1874, Jean-Maurice-Émile Baudot developed a “printing telegraph” with a new character code- 5 bit Baudot code. It increased the speed of encoding significantly with a special, 5 key keyboard that operators used with each finger.
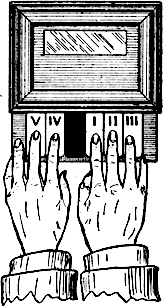
The Baudot telegraph machine. Image from Telegraphy Golf.
Baudot is 5 bit, which means 32 “code points” (2^5). This is less characters than Morse code had (A-Z, numerals, punctuation marks), so Baudot code had “two planes” of 32 elements each, which could be selected from. (Think about how you pick a keyboard on your phone, or use the shift key on your computer - both technological echoes from Baudot.)
Because of this shifting function, Baudot has something called control codes, which later became a fundamental part of code points in early computers. These “control codes” told the device which plane to select from. We’ll talk more about them later.
The last historical character code I want to talk about doesn’t actually come from the telegraph or other early telecommunication- rather it was created for the 1890 US census, by Herman Hollerith. Hollerith created a standardized character code for encoding alphanumeric data on punch cards, which has had long-lasting effects in computation and a legacy we still carry today.

A Jacquard Loom. Image from Wikimedia Commons.
Punch cards were brought into the public eye around 1800 by Joseph-Marie Jacquard, used in a new loom for weaving patterns into fabric. The Jacquard Loom was the first fully automatic loom, and also proved inspiration for Babbage’s and Lovelace’s contributions to the “analytical engine”, which was never implemented but was, in theory, our first mechanical computer.
Herman Hollerith came up with a standardization of this approach, which was a stiff card with 12 rows and 80 columns. When punched and fed through a reader, pins would pass through these 12 holes and complete a circuit, which could then be recorded. The usage of these cards cut down the time taking to complete the US census from 7 years (in 1870) to 6 weeks (in 1880).
In this system, there were 69 elements- uppercase Latin letters, Arabic numerals, punctuation marks, and various symbols. Even though the system only had only 69 characters, it used 12 rows- which meant you could encode characters with a small number of punches, just like how Morse used a single dit for E. This low-punch design was so that human punchers would have minimal labor.
Hollerith went into business with the machine in 1896, which after a series of mergers became Computing-Tabulating-Recording Co. in 1911, which changed its name to International Business Machines Corporation in 1924, an acronym you may be familiar with still. These punch-card technologies were used at IBM and other companies for data and character representation until the 1960s!

A Computing-Tabulating-Recording Company product poster from 1933, courtesy of the IBM Corporate Archive.
Of course, this is an oversimplification of the narrative, with a focus on American computing centers which came to dominate the market later on, and so wrote their own histories. There were many competing telegraph standards from countries who did not use “international Morse”. This is particularly present in East Asian telegraph codes, which had a very different set of character requirements than western languages.
For instance, Chinese telegraph code came with a codebook that maps a 1-1 correspondence from Chinese characters to numbers between 0000 to 9999. The arrangement of these characters is due to their radicals and strokes, which then you can reference in the book (which is quite similar to Unicode now, as we’ll see later on).
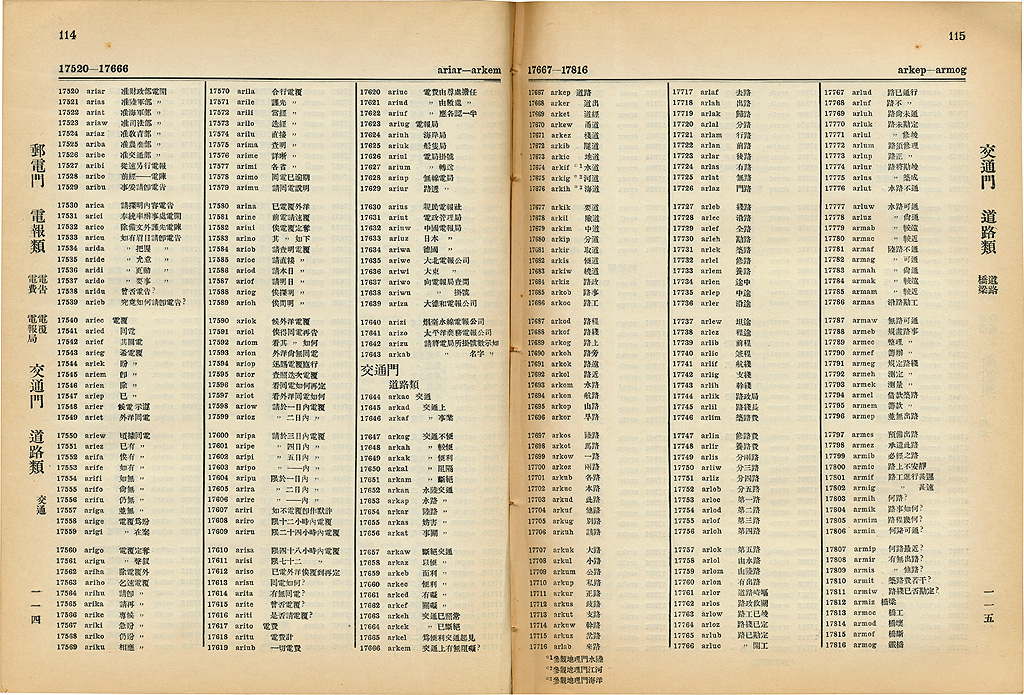
Pages 114-115, The China Republican Telegraphic Code, 1915. Image from jcmvey.net.
To send a message in Chinese telegraph code, you would send the numbers of the characters. “Information in Chinese,” is rendered into the code as 0022 2429 0207 1873, which is then transmitted using Morse code. Receivers decode the Morse code to get a sequence of digits, chop it into an array of quadruplets, and then decode them one by one referring to the book.
By the 1960s even in countries with relatively few necessary codepoints, it was becoming clear that the limited range of Morse and Baudot code was not enough. Computers needed to handle the same sets of characters as a typewriter. This is because data was increasingly moving between typed document and computing machine, and computers were becoming networked for communication and data storage- not simply being used as number crunchers.
On to Chapter III - ASCII and character encoding.
{kind=link}